

在過去的一週裡,我看到了許多反對深入研究 2,596 頁的爭論。
但我們應該問自己的唯一問題是: “我怎麼能嘗試從這些文件中盡可能多地學習?”
SEO 是一門應用科學,理論不是最終目標,而是實驗的基礎。
 圖片來源:Lyna™
圖片來源:Lyna™透過《成長備忘錄》每週的專家見解來提升您的技能。 免費訂閱!
14,000 個測試想法
沒有比這更好的測試想法的溫床了。 但我們不能以同樣的方式測試所有因素。 它們具有不同的類型(數字/整數:範圍,布林值:是/否,字串:單字/列表)和反應時間(即它們導致有機範圍變化的速度)。
因此,我們可以對快速和主動因素進行 A/B 測試,而必須對慢速和被動因素進行前/後測試。
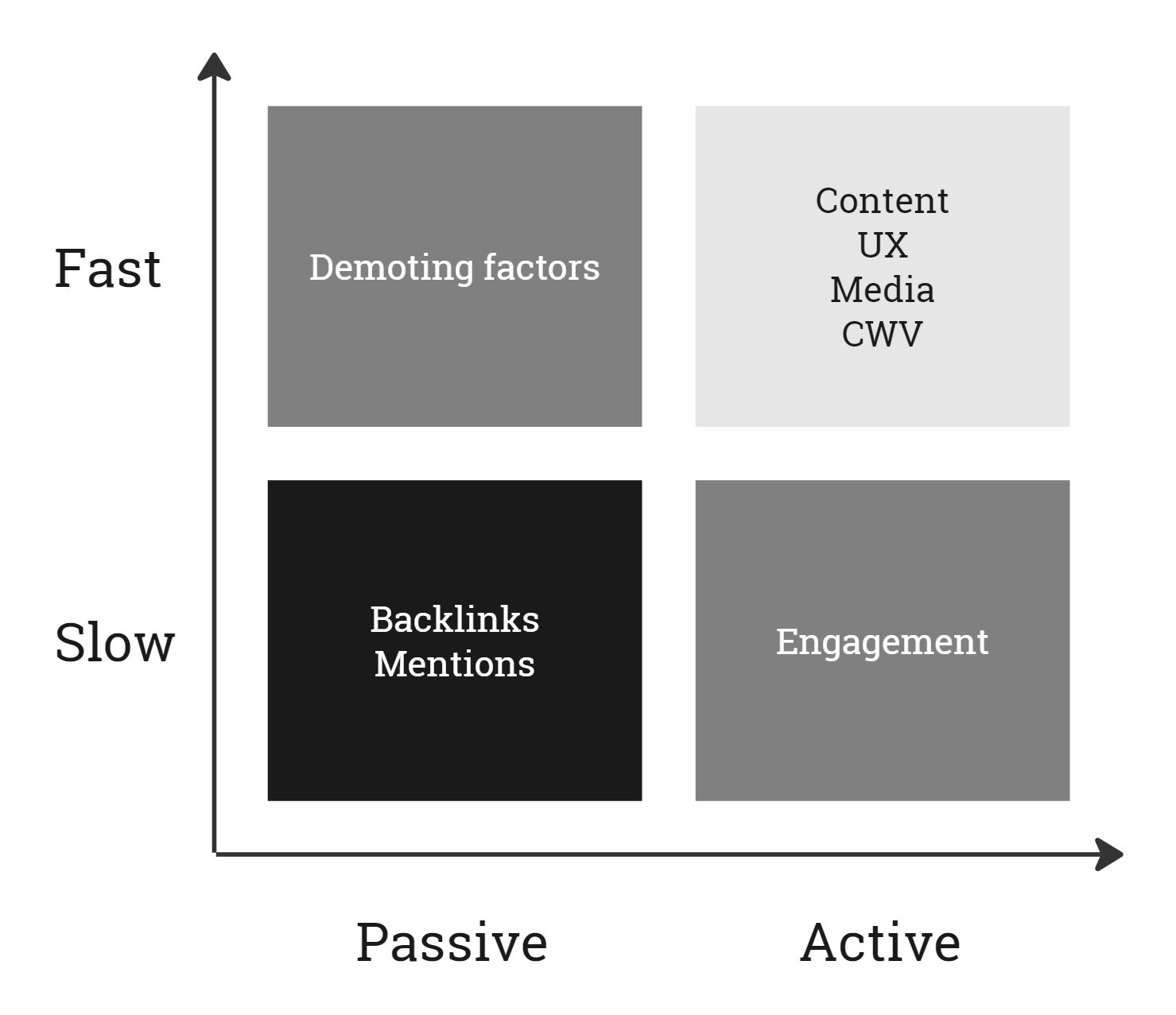 按速度決定測試優先順序。 (圖片來源:凱文英迪格)
按速度決定測試優先順序。 (圖片來源:凱文英迪格)透過以下方式系統性地檢視排名因素:
- 分類因子的選擇。
- 選擇受影響的(成功)指標。
- 定義測試的位置。
- 定義測試類型。
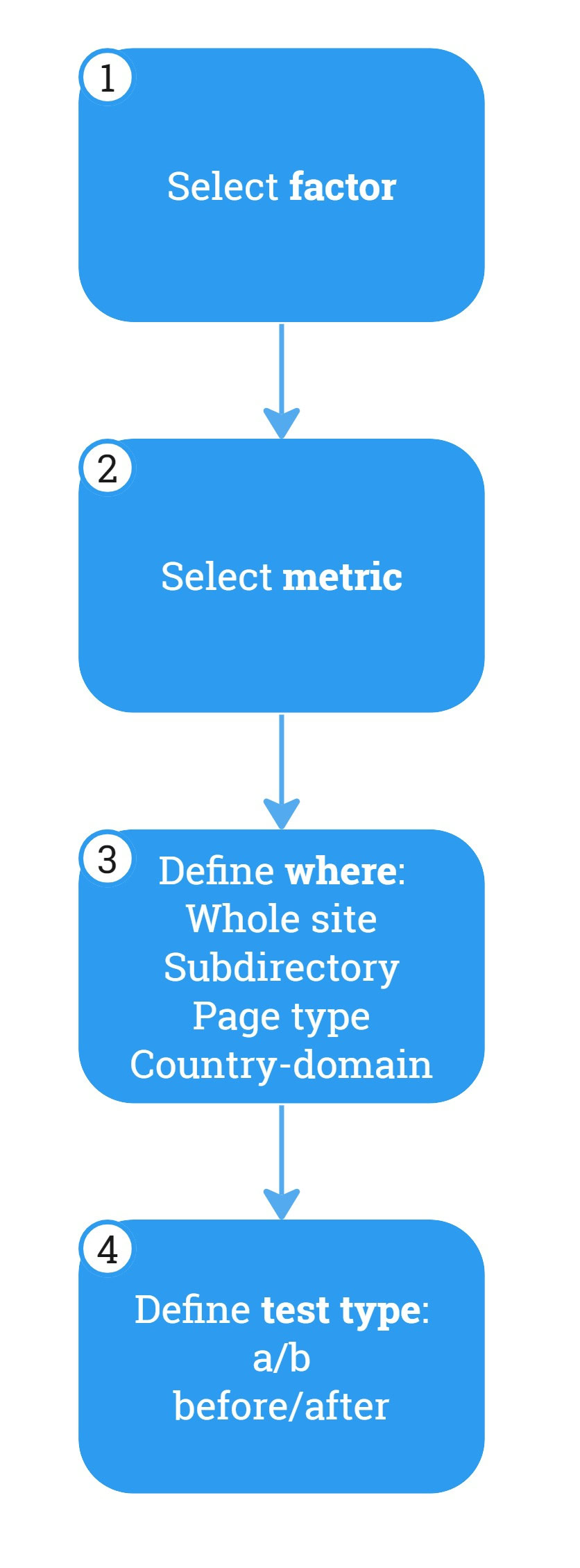 圖片來源:凱文英迪格
圖片來源:凱文英迪格分類因素
大多數過濾器排名因素都是整數,這意味著它們在一個範圍內工作,但一些布林因素很容易測試:
- 影像壓縮:是/否?
- 侵入式插頁式廣告:是/否?
- 核心網路生命:是/否?
您可以直接控制的因素:
- 使用者體驗(導航、字體大小、行距、影像品質)。
- 內容(新鮮標題、優化、非重複、相關實體豐富、關注用戶意圖、付出巨大努力、註明原始來源、使用單字的規範形式而不是行話、高品質的 UGC、專家作者)。
- 使用者參與(任務完成率高)。
降級(負面)分類因素:
- 來自低品質頁面和網域的連結。
- 激進的錨文本(除非您有非常強大的連結配置)。
- 導航不好。
- 用戶訊號不佳。
您只能被動影響的因素:
- 來源文檔和連結文檔之間的標題匹配和相關性。
- 連結點擊。
- 來自新頁面和受信任頁面的連結。
- 域權限。
- 品牌提及。
- 首頁的 PageRank。
首先評估您在要測試的領域的表現。 一個簡單的用例是 Core Web Vitals。
指標
根據過濾後的文件描述或您對因素如何影響指標的理解,為正確的因素選擇正確的指標:
- 爬行速度
- 索引(是/否)。
- 排名(針對主要關鍵字)。
- 點擊率(CTR)。
- 承諾
- 頁面排名的關鍵字。
- 有機點擊。
- 印象數
- 豐富的片段。
去哪裡嘗試
找到適合的地方嘗試:
- 如果您持懷疑態度,請使用特定於國家/地區的網域或可以進行低風險測試的地方。 如果您有多個語言的網站,您可以根據國家/地區洩漏實施更改,並將相對性能與您的主要國家/地區進行比較。
- 您可以將測試限制為頁面的一種類型或子目錄,以盡可能隔離影響。
- 將測驗限制在涉及特定類型關鍵字(例如“Best X”)或使用者意圖(例如“閱讀評論”)的頁面。
一些排名因素是網站範圍的訊號,例如網站權限,而其他因素是特定於頁面的,例如點擊率。
注意事項
分類 因素 它們可以相互合作,也可以相互對抗,因為它們是一個等式的一部分。
眾所周知,人類不善於直觀地理解具有許多變數的函數,這意味著我們很可能會低估用於獲得高分的因素,以及某些變數如何顯著影響結果。
分類因素之間關係的高度複雜性不應妨礙我們進行實驗。
聚合器比整合器更容易測試,因為它們擁有更多可比較的頁面,可以產生更有意義的結果。 整合商必須自行創建內容,每個頁面之間存在差異,從而稀釋了測試結果。
我最喜歡的測試: 為了理解 SEO,你可以做的最好的事情之一就是根據你自己的看法對排名因素進行評分,然後系統地挑戰和測試你的假設。 建立一個包含每個排名因素的電子表格,根據您對其重要性的看法給它一個介於 0 和 1 之間的數字,然後將所有因素相乘。
監控系統
這些測試僅給我們關於排名因素重要性的初步答案。 追蹤使我們能夠衡量一段時間內的關係並得出更有力的結論。
這個想法是追蹤反映排名因素的指標,例如點擊率可以反映標題優化,並隨著時間的推移繪製它們以查看優化是否得到回報。 除了新指標之外,這個想法與常規(或應該是)常規追蹤沒有什麼不同。
您可以在以下位置建立監控系統:
- 觀點
- 寬度。
- 混合面板。
- 木板
- 圓頂
- 壁虎板。
- 好數據。
- 電力商業智慧。
該工具並不像正確的指標和 URL 路徑那麼重要。
指標範例
隨著時間的推移,按頁面類型或 URL 集衡量指標,以衡量優化的影響。
注意:我使用的閾值是基於我的個人經驗,您應該挑戰。
用戶參與:
- 導航中的平均點擊次數。
- 平均位移深度。
- 點擊率(網站 SERP)。
反向連結品質:
- 與來源和目標之間的主題/標題高度匹配的連結的百分比。
- 來自不到 1 年的頁面的連結百分比。
- 至少有一個關鍵字排名前 10 名的頁面連結的百分比。
頁面品質:
- 平均停留時間(相同類型頁面之間的比較)。
- 在網站上花費至少 30 秒的用戶所佔的百分比。
- 目標關鍵字排名前 3 名的網頁百分比。
網站品質:
- 產生自然流量的頁面百分比。
- 過去 90 天內未點擊的 URL 的百分比。
- 索引頁面和非索引頁面之間的關係。
諷刺的是,這次洩密事件發生在Google開始展示人工智慧結果(人工智慧概述)之後不久,因為我們可以使用人工智慧根據洩密事件找到 SEO 差距。
一個例子是匹配反向連結的來源標題和目標標題。 使用標準 SEO 工具,我們可以提取標題、錨文本和周圍連結內容以用於引用和登陸頁面。
然後,我們可以使用常見的人工智慧工具、本地 Google Sheets/Excel 或 LLM 整合以及基本提示(例如 “以 1 到 10 的等級,對標題(B 列)與錨點(C 列)的主題接近度進行評分,10 表示完全相同,1 表示完全沒有關係。”
 使用人工智慧評估連結來源和目標之間的標題匹配。 (圖片來源:凱文英迪格)
使用人工智慧評估連結來源和目標之間的標題匹配。 (圖片來源:凱文英迪格)自己的過濾器
谷歌排名因素的洩漏並不是第一次向公眾公開主要平台演算法的內部運作方式:
1. 2023 年 1 月,Yandex 洩密事件揭示了許多排名因素,我們也在最新的 Google 洩密事件中發現了這些因素。 當時和現在一樣,這種平淡的反應讓我感到驚訝。
2. 2023年3月,Twitter發布了大部分演算法。 與Google洩密事件類似,它缺乏因素之間的“背景”,但仍然具有洞察力。
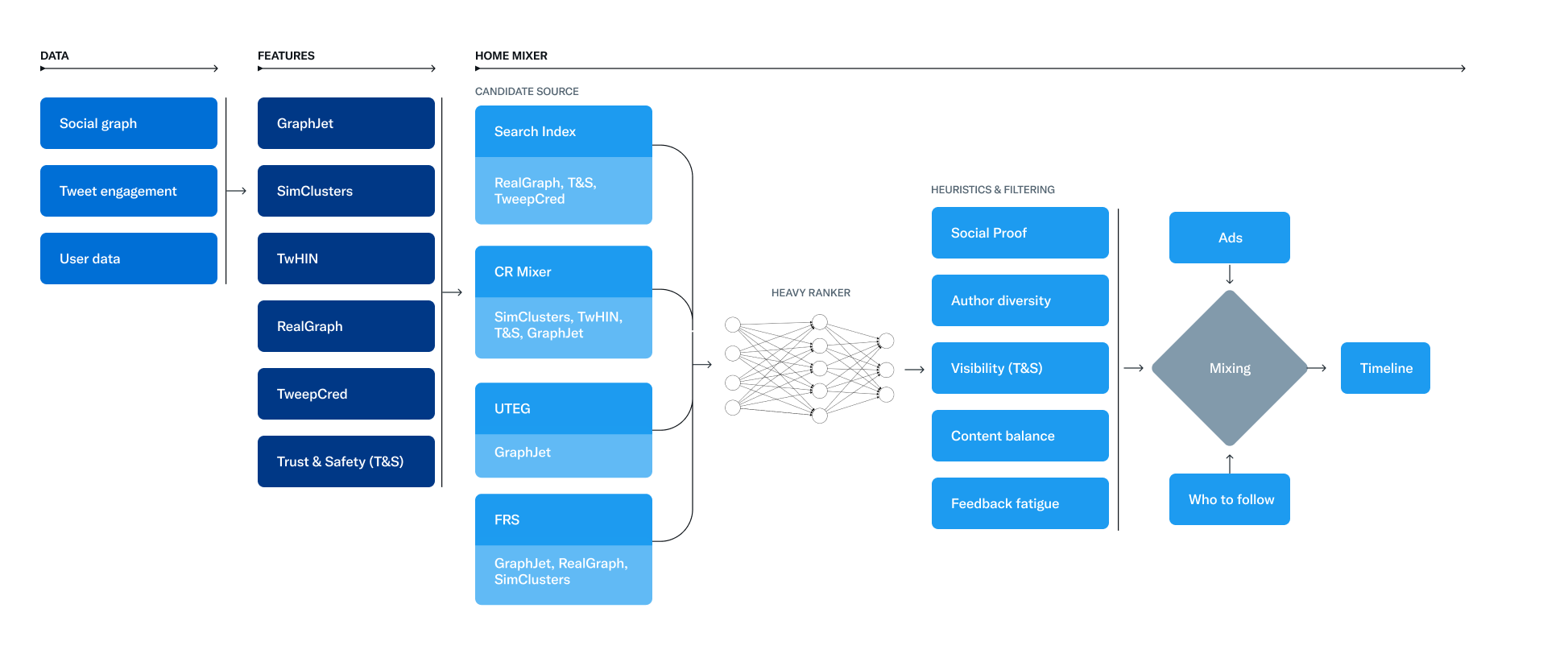 系統圖中的 Twitter 演算法。 (圖片來源:凱文英迪格)
系統圖中的 Twitter 演算法。 (圖片來源:凱文英迪格)3. 同樣在 2023 年 3 月,Instagram 老闆 Adam Mosseri 發表了一篇深入的後續文章,介紹該平台如何將內容分類到其產品的不同部分。
儘管存在洩密事件,但尚無用戶或品牌以乾淨且道德的方式入侵平台的已知案例。
平台對演算法的參與度獎勵越多,玩起來就越難。 然而,Google的演算法洩漏非常有趣,因為它是一個基於意圖的平台,用戶透過搜尋而不是行為來表明他們的興趣。
因此,即使不知道每種蛋糕的用量,了解蛋糕的成分也是向前邁出的一大步。
我不明白為什麼谷歌一直對排名因素如此保密。 我並不是說我應該將它們發佈到洩漏的程度。 它本可以鼓勵建立一個更好的網絡,提供快速、易於導航、有吸引力且資訊豐富的網站。
相反,它讓人們猜測太多,從而導致內容不佳,進而導致演算法更新,讓許多公司損失了大量資金。
Github.com系統圖
Instagram 排名解釋
特色圖片:Paulo Bobita/搜尋引擎雜誌