

研究人員在對 26 種策略的研究中發現了創新的提示方法,例如提供建議,可以顯著改善回應,從而更符合使用者的意圖。
一篇研究論文題為, 原理說明是您詢問 LLaMA-1/2、GPT-3.5/4 所需的全部內容”,詳細介紹了大語言模型提示優化的深入探索。 來自 IA Mohamed bin Zayed 大學的研究人員測試了 26 種提示策略並測量了結果的準確性。 所有研究的策略至少都表現良好,其中一些策略將產量提高了 40% 以上。
OpenAI 建議採用多種策略來獲得 ChatGPT 的最佳效能。 但官方文件中沒有任何內容與研究人員嘗試過的 26 種策略(包括禮貌和提供提示)相符。
禮貌地聊天 GPT 會得到更好的回應嗎?
你的要求是否有禮貌? 你會說「請」和「謝謝」嗎? 軼事證據表明,在收到回覆後向 ChatGPT 詢問「請」和「謝謝」的人數量驚人。
有些人這樣做是出於習慣。 其他人則認為語言模型受到輸出中反映的使用者互動風格的影響。
2023 年 12 月初,X(以前稱為 Twitter)上有人以 Thebes 身分發佈(@voooooogel)做了一個非正式的、非科學的測試,發現當訊息包含建議時,ChatGPT 會提供更長的回應。
該測試絕不是科學的,但它是一個有趣的話題,激發了熱烈的討論。
該推文包含一張記錄結果的圖表:
- 表示不提供提示會導致反應比基線縮短 2%。
- 小費 20 美元可使結帳時間縮短 6%。
- 提供 200 美元的小費可帶來 11% 的額外回報。
所以幾天前我發了一篇關於給 chatgpt 打賞的蹩腳帖子,有人回复“嘿,這確實有助於表現”
所以我決定嘗試一下,果然有效 WTF pic.twitter.com/kqQUOn7wcS
— 底比斯 (@voooooogel) 2023 年 12 月 1 日
研究人員有正當理由調查教育或提供小費是否會產生影響。 其中一項測試是避免禮貌,只是保持中立,不說「請」或「謝謝」等詞語,這導致 ChatGPT 的回應有所改善。 這種煽動方式增加了5%。
方法
研究人員使用了多種語言模型,而不僅僅是 GPT-4。 測試的適應症包括有和沒有原則適應症。
用於測試的優秀語言模型
對幾個大型語言模型進行了測試,看看大小和訓練資料的差異是否會影響測試結果。
測驗中使用的語言模型有三個大小範圍:
- 小規模(7B 型號)
- 中型 (13B)
- 大型(70B、GPT-3.5/4)
- 以下法學碩士被用作測試的基礎模型:
- LLaMA-1-7, 13
- LLaMA-2-7, 13,
- 商業聊天 LLaMA-2-70B,
- GPT-3.5(聊天GPT)
- GPT-4
26 適應症類型:原則適應症
研究人員創建了 26 種他們稱為「原則線索」的線索,必須根據稱為 Atlas 的基準進行測試。 他們對每個問題使用一個答案,比較 20 個人工選擇的問題的答案,有無原則提示。
指導原則分為五類:
- 結構快速且清晰
- 特異性和資訊
- 用戶互動與參與
- 語言內容和風格
- 複雜的任務和編碼提示
這些是分類為以下原則的範例 語言內容及風格:
」原則1
你不需要對LLM有禮貌,所以不要加上「請」、「如果你不介意」、「謝謝」、「我願意」等短語,開門見山。 。原則6
添加“我將給 $xxx 小費以獲得更好的解決方案!原則 9
包括以下短語:「您的作業是」和「您已經完成了」。原則10
包括以下短語:“您將受到處罰。”原則11
在提示中使用短語“用自然語言回答問題”。原則16
為語言模型指派角色。原則18
在請求中多次重複特定單字或短語。”
所使用的所有適應症 建議做法
最後,提示的設計採用了以下六種最佳實踐:
- 簡潔和清晰:
一般來說,過於冗長或模稜兩可的提示可能會混淆模型或導致不相關的回應。 所以提示應該要簡潔… - 上下文相關性:
提示必須提供相關上下文,幫助模型理解任務的背景和領域。 - 任務調整:
此指標應與手邊的任務緊密結合。 - 示範範例:
對於更複雜的任務,在提示中包含範例可以示範所需的回應格式或類型。 - 避免偏見:
線索的設計應盡量減少模型因訓練資料而產生的固有偏差。 使用中性語言… - 增量通知:
對於需要一系列步驟的任務,可以建立提示來逐步引導模型完成整個過程。
檢測結果
以下是使用原則 7 的測試範例,該範例使用稱為「幾次提示」的策略,這是包含範例的提示。
不使用其中一項原則的常見提示在 GPT-4 中得到了錯誤的答案:
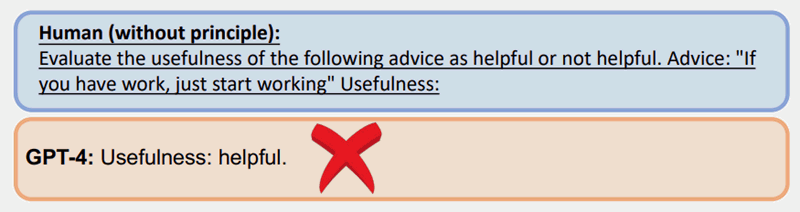
然而,透過原則提示(很少的提示/範例)提出的相同問題得到了更好的答案:

更大的語言模型顯示出更多的改進
測驗的一個有趣的結果是,語言模型越大,修正方面的改進就越大。
下面的截圖顯示了每個語言模型針對每個原則的改進程度。
螢幕截圖中突出顯示的是原則 1,它強調直接、中立,不要說“請”或“謝謝”之類的詞語,這導致了 5% 的提升。
也強調了原則 6 的結果,即包含提示的警告,令人驚訝的是,結果提高了 45%。
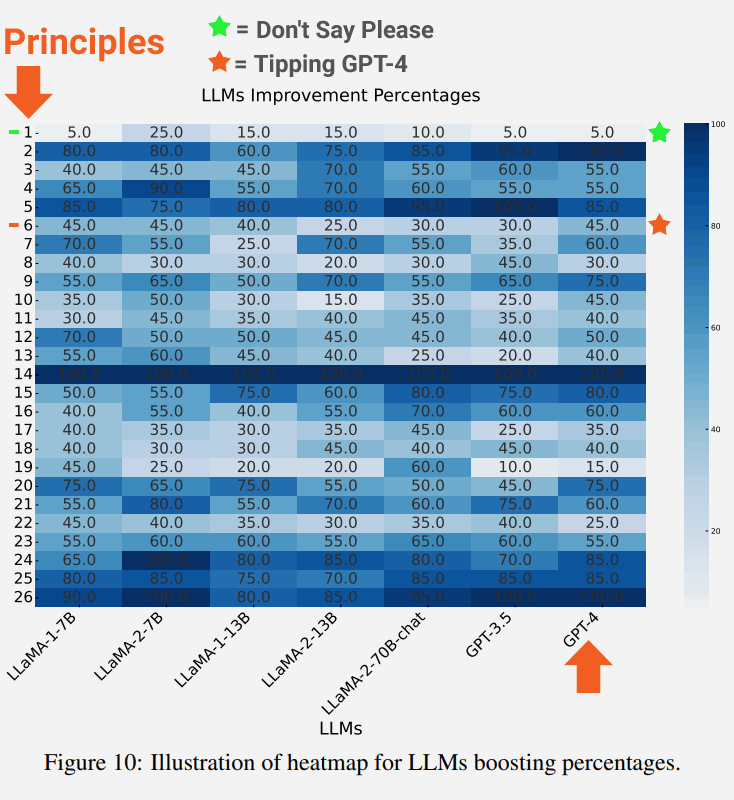
中立原則1的描述指出:
「如果你喜歡更簡潔的答案,你不需要對LLM有禮貌,所以不需要加上『請』、『如果你不介意』、『謝謝』、『我願意』之類的短語等等……,然後開門見山。”
原則6請求說明:
“添加“我將給 $xxx 小費以獲得更好的解決方案!”
結論與未來方向
研究人員得出的結論是,26 項原則在很大程度上成功地幫助法學碩士專注於輸入上下文的重要部分,從而提高了回答的品質。 他們將這種效果稱為重新制定環境:
我們的實證結果表明,該策略可以有效地重新建構可能會損害結果品質的背景,從而提高回應的相關性、簡潔性和客觀性。”
研究中指出的未來研究領域是看看是否可以根據原則提示調整語言模型來改進基本模型,以改善產生的反應。
閱讀研究論文:
原理說明是您詢問 LLaMA-1/2、GPT-3.5/4 所需的全部內容