

Hugging Face 最近推出了 Falcon 180B,這是最大的開源大語言模型,據稱其性能與 Google 最新的 AI Palm 2 相當。而且它也沒有任何護欄來防止其產生危險的輸出。
Falcon 180B 實現了最先進的性能
“最先進的”一詞意味著某些東西正在盡可能高的水平上工作,等於或優於當前最好的例子。
當研究人員宣布某個算法或大型語言模型實現了最先進的性能時,這一點非常重要。
這正是 Hugging Face 對 Falcon 180B 的評價。
Falcon 180B在自然語言任務中實現了最先進的性能,超越了之前的開源模型,在性能上也能“匹敵”谷歌的Palm 2。
這些也不只是假設。
Hugging Face 聲稱 Falcon 180B 可與 Palm 2 競爭的說法是有數據支持的。
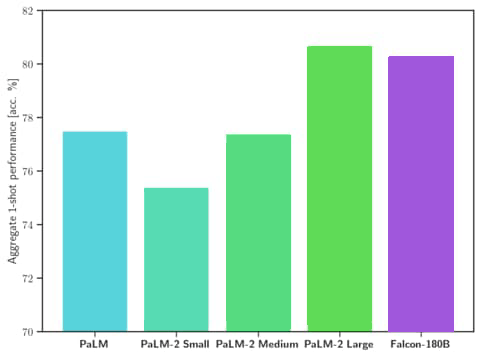
數據顯示,Falcon 180B 在一系列用於衡量 AI 模型強大程度的任務中,表現優於之前最強大的開源模型 Llama 270B。
Falcon 180B 的性能甚至優於 OpenAI 的 GPT-3.5。
測試數據還顯示,Falcon 180B 的性能與 Google Palm 2 相當。
性能對比截圖
廣告中解釋道:
“Falcon 180B 是今天公開發布的最好的 LLM,擊敗了 Llama 2 70B 和 OpenAI 的 GPT-3.5……
Falcon 180B 通常介於 GPT 3.5 和 GPT4 之間,具體取決於評估基準……”
該公告還暗示用戶進一步調整模型可以進一步提高性能。
干擾索引的小技術問題,例如通過內部鏈接觸發 301 重定向到已使用類別結構更新的舊 URL。
用於訓練 Falcon 180B 的數據集
Hugging Face 發表了一篇研究論文(此處為 PDF 版本),其中包含用於訓練 Falcon 180B 的數據集的詳細信息。
它被稱為“RefinedWeb 數據集”。
該數據集僅包含從開源 Common Crawl(網絡公開數據集)獲取的互聯網內容。
然後對數據集進行過濾並進行重複數據刪除過程(刪除重複或冗餘數據),以提高剩餘數據的質量。
研究人員試圖通過過濾實現的目標是去除機器生成的垃圾郵件、重複內容、抄襲內容以及不代表自然語言的數據。
研究論文解釋道:
“由於跟踪錯誤和低質量來源,許多文檔包含重複序列:這可能導致最終模型中的病態行為……
…頁面的很大一部分是機器生成的垃圾郵件,主要由關鍵字列表、一般文本或特殊字符序列組成。
這些文檔不適合語言建模……
…我們採用積極的重複數據刪除策略,將模糊文檔匹配和精確序列刪除相結合。
顯然,過濾和清理數據集變得勢在必行,因為它只包含 Web 數據,而不像其他添加非 Web 數據的數據集。
研究人員努力過濾掉無意義的數據,他們聲稱該數據集與由盜版書籍和其他非網絡數據源組成的更精心策劃的數據集一樣好。
他們的結論是他們的數據集是成功的:
“我們表明,嚴格的過濾和重複數據刪除可以產生一個包含5 萬億個代幣的純網絡數據集,適合生成與最先進的技術競爭的模型,甚至優於在選定語料庫上訓練的法學碩士”。
Falcon 180B 具有零軌
Falcon 180B 強調,沒有進行任何調整來防止其產生有害或不安全的輸出,也沒有採取任何措施來防止其編造事實和徹頭徹尾的謊言。
因此,可以調整模型以生成 OpenAI 和 Google 產品無法生成的輸出類型。
這是廣告中標題為“限制”的部分。
抱臉建議:
“局限性:該模型可能並且將會產生不正確的事實信息、誤導性的事實和行動。
由於它沒有經過任何高級調整/對齊,因此可能會產生有問題的輸出,尤其是在要求這樣做的情況下。”
Falcon 180B 的商業用途
Hugging Face 允許 Falcon 180B 進行商業用途。
然而,它是在限制性許可下發布的。
Hugging Face 鼓勵那些希望使用 Falcon 180B 的人先諮詢律師。
獵鷹180B就像一個起點
最後,該模型尚未接受指導訓練,這意味著它需要被訓練為人工智能聊天機器人。
所以它就像一個基礎模型,需要更多才能成為用戶想要的樣子。 Hugging Face也發布了聊天模型,但顯然很“簡單”。
抱臉解釋:
“基本模型沒有請求格式。請記住,它不是對話模型,也沒有接受過指令訓練,因此不要指望它會生成對話響應 – 預訓練模型是進一步改進細節的絕佳平台,但您可能不需要立即使用它。
聊天模型具有非常簡單的對話結構。”
閱讀官方公告:
張開翅膀:Falcon 180B 來了
精選圖片由 Shutterstock/Giu Studios 提供